FrontierMath is the current end boss of math problems for AI. The problems are organized into four tiers. Tier 1 is supposed to be roughly equivalent to international mathematics olympiad problems (i.e. really hard, can take hours to solve or sometimes stump even the very top young math talent), and tier 4 is supposed to represent research-level problems that might take a week to solve for a professional math researcher with all available tools at their disposal. Here is a sample tier 1 problem:

I thought for about 20 minutes, but didn’t come close to solving it. But it does feel approachable.
At tier 4, we have:

I have no idea where to even begin. The model solution is multiple pages long, and it’s that short only because it assumes that the reader is familiar with three research papers published by the authors of the problem.
How are the AI models doing on these problems? Surely tier 4 is out of reach? Nope! Here is the leaderboard for tier 4:
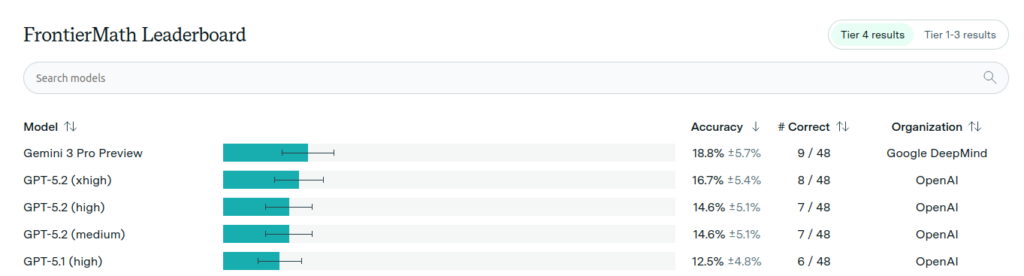
Gemini 3 Pro Preview is claimed to have solved 9/48 of the tier 4 problems. On social media, this is being framed as AI failing on the vast majority of the problems. I think that’s a totally backwards interpretation. The real story here is that AI solved almost one fifth of these problems! Incredible. This should be huge news, right? Doesn’t this imply that we might be just a few breakthroughs away from AI matching top humans in well-defined problem solving tasks like these? Why is no one talking about this?
There has been some speculation that OpenAI might have an unfair advantage here because they were the ones to commission this benchmark, and they apparently have access to problems in the test set. Okay, fair enough, that could be an issue, but the current top score on the leaderboard is from Google DeepMind, not OpenAI.
But then, I finally found a reasonable explanation for the scores. In a tweet from July 2025 from Epoch AI (the institute that created the benchmark), they wrote that AIs simplified the problems based on unjustified assumptions:

So they arrived at the right answer, but did not provide the full reasoning for why the answer is correct. That is actually the most important part of math. The reasoning traces are not published, so it’s hard to evaluate whether the models really did the reasoning or just took probable-looking shortcuts.
This situation highlights how hard it is to come up with automatically verifiable benchmarks for advanced reasoning.
I think that the takeaway is that we need to start demanding machine-checkable proofs, like those written in Lean. Currently, AI struggles to formalize even known mathematics in Lean, even with access to human-written proofs. So we are clearly missing something. I think that instead of focusing on the FrontierMath benchmark, a more fruitful direction for AI companies would be to try to get the models to understand known mathematics well enough to formalize them in Lean. I think that if that succeeds, then novel mathematics will also start to follow.
Is Lean too simplistic for real mathematics? How about giving the AI the task of coming up with a proof system that is better than Lean. Now THAT would be impressive.
(edit 27.12.: Elliot Glazer, the lead developer of FrontierMath, pointed out on Reddit that some of the Tier 4 problems have now been solved essentially in the intended way by AI: tweet.)